Последовательности: списки, кортежи и строки
Contents
Последовательности: списки, кортежи и строки¶
И снова про типы данных.
Следующие встроенные контейнеры являются последовательностями (sequence types):
list*— списки;tuple— кортежи;range— диапазоны;str— строки;bytes,bytearray*— бинарные данныеarray*и некоторые другие. Изменяемые типы данных помечены символом “*”.
Все последовательности упорядочены (пронумерованы). Это означает возможна их индексация по смещению (zero-based), т.е. если s — объект-последовательность, i, j и k — индексы (целые числа), то доступные следующие операции.
Операция |
Описание |
|---|---|
|
|
|
Срез |
|
Срез |
Общие для последовательностей операции¶
Следующие операции можно совершать почти над любыми последовательностями.
Операция |
Описание |
|---|---|
|
Длинна |
|
|
|
Отрицание |
|
Конкатенация |
|
Эквивалентно добавлению |
|
Наименьший элемент в |
|
Наибольший элемент в |
|
Индекс первого совпадения |
|
Количество раз |
Принадлежность контейнеру¶
С точки зрения python контейнер определяется тем, что у него всегда можно спросить, лежит ли какой-то элемент x в этом контейнере. Если container — контейнер, то проверка на наличие элемета x в нем осуществляется это синтаксисом x in container.
Любая последовательность является в том числе и контейнером, но обратное не верно. Позже мы познакомимся с словарями и множествами, которые являются контейнерами, но не последовательностями.
Код в ячейке ниже удостоверяет, что символ "a" присутствует в строке "abc", а символ "x".
s = "abc"
print("a" in s)
print("z" in s)
True
False
Для строк операция проверки на принадлежность работает несколько шире, чем для остальных контейнеров: можно проверять наличие сразу подстроки.
print("ab" in s)
print("ac" in s)
True
False
Вместо того, чтобы отрицать результат проверки на принадлежность, можно проверять на непринадлежность сразу.
print("z" not in s)
True
У последовательностей можно спрашивать более содержательные вопросы, чем просто факт наличия элемента в контейнере. Например, методом index можно узнать индекс первого вхождения элемента x в последовательность s.
s = "Hello, World!"
i = s.index("o")
print(i, s[i])
4 o
Методом count можно посчитать количество вхождений элемента x в последовательность s.
print(s.count("o"))
2
Сложение и умножение последовательностей¶
Последовательности одного вида (кроме range) можно конкатенировать знаком плюс.
from string import ascii_lowercase, ascii_uppercase
print(ascii_lowercase + ascii_uppercase)
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
Умножение последовательности s (кроме range) на целое число n эквивалентно конкатенации s с самой собой n раз.
x = "abc"
print(x*5)
abcabcabcabcabc
Упорядочивание элементов последовательности¶
Операции в этом подразделе поддерживаются, вообще говоря, всеми итерируемыми объектами, т.е. контейнерами, по элементам которого можно пробежаться в каком-то порядке. Все последовательности являются итерируемыми объектами, т.к. по их элементам можно пробежаться хотя бы в порядке, в котором они пронумерованы.
Если элементы итерируемого объекта однородны, т.е. их можно сравнить друг с другом на предмет большинства и равенства, то их можно сортировать искать минимальное и максимальное значение в них.
Например, символы английского алфавита упорядочиваются python в согласии с алфавитным порядком, при этом строчные буквы идет позже прописных.
print("A" < "Z")
print("A" < "a")
True
True
Встроенные функции min и max находят минимальный и максимальный элементы итерируемого объекта соответственно.
Код в ячейке удостоверяет, что буква "h" идет раньше всех в алфавите среди всех букв слова "python".
from random import randint
x = "python"
print(min(x), max(x))
h y
Встроенная функция sorted принимает на вход итерируемый объект и возвращает список его элементов в отсортированном порядке.
print(sorted(x))
['h', 'n', 'o', 'p', 't', 'y']
Опциональный именованный параметр reverse позволяет сортировать в обратном порядке.
print(sorted(x, reverse=True))
['y', 't', 'p', 'o', 'n', 'h']
Note
На самом деле python упорядочивает символы согласно их unicode кодам. В таблицу символов unicode входят в том числе и emoji, что позволяет средствами python ответить на извечный вопрос: “Что появилось раньше, яйцо или курица?”.
chicken = chr(0x1f414)
egg = chr(0x1f95a)
print(chicken, egg)
print(sorted([egg, chicken]))
🐔 🥚
['🐔', '🥚']
Здесь встроенная функция chr делает символ из его unicode кода, который в примере выше задаётся в шестнадцатеричной системе счисления, чем и объясняется наличие префикса 0x и цифр abcdef в числе. Встроенная функция ord совершает обратную операцию, т.е. принимает на вход символ и возвращает его код.
Списки. list¶
Под капотом списки реализованы в виде динамического массива (похожего на std::vector) указателей на его элементы.
Создать список можно несколькими способами:
Парой квадратных скобок, чтобы обозначить пустой список:
[];
empty_list = []
print(empty_list)
[]
Используя пару квадратных скобок и разделяя элементы списка запятыми:
[a],[a, b, c];
singleton_list = [42]
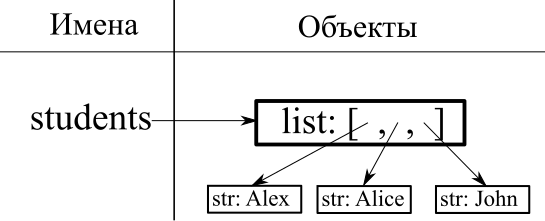
students = ["Alex", "Alice", "John"]
print(singleton_list, students)
[42] ['Alex', 'Alice', 'John']
Используя конструктор типа:
list()илиlist(iterable);
letters = list(ascii_lowercase)
print(letters)
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Используя списковые включения (
list comprehensions):[x for x in iterable]
square = [x*x for x in range(5)]
print(square)
[0, 1, 4, 9, 16]
List comprehensions — очень мощный инструмент для работы со списками и будет обсуждаться позже в разделе Основы списковых включений.
Создание списков с помощью умножения¶
Выражение [x] * n может быть использовано для того, чтобы создавать не пустой список, а список из n одинаковых элементов x. В качестве примера создадим нулевой n мерный вектор.
v = [0] * 10
print(v)
v[0] = 1
print(v)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
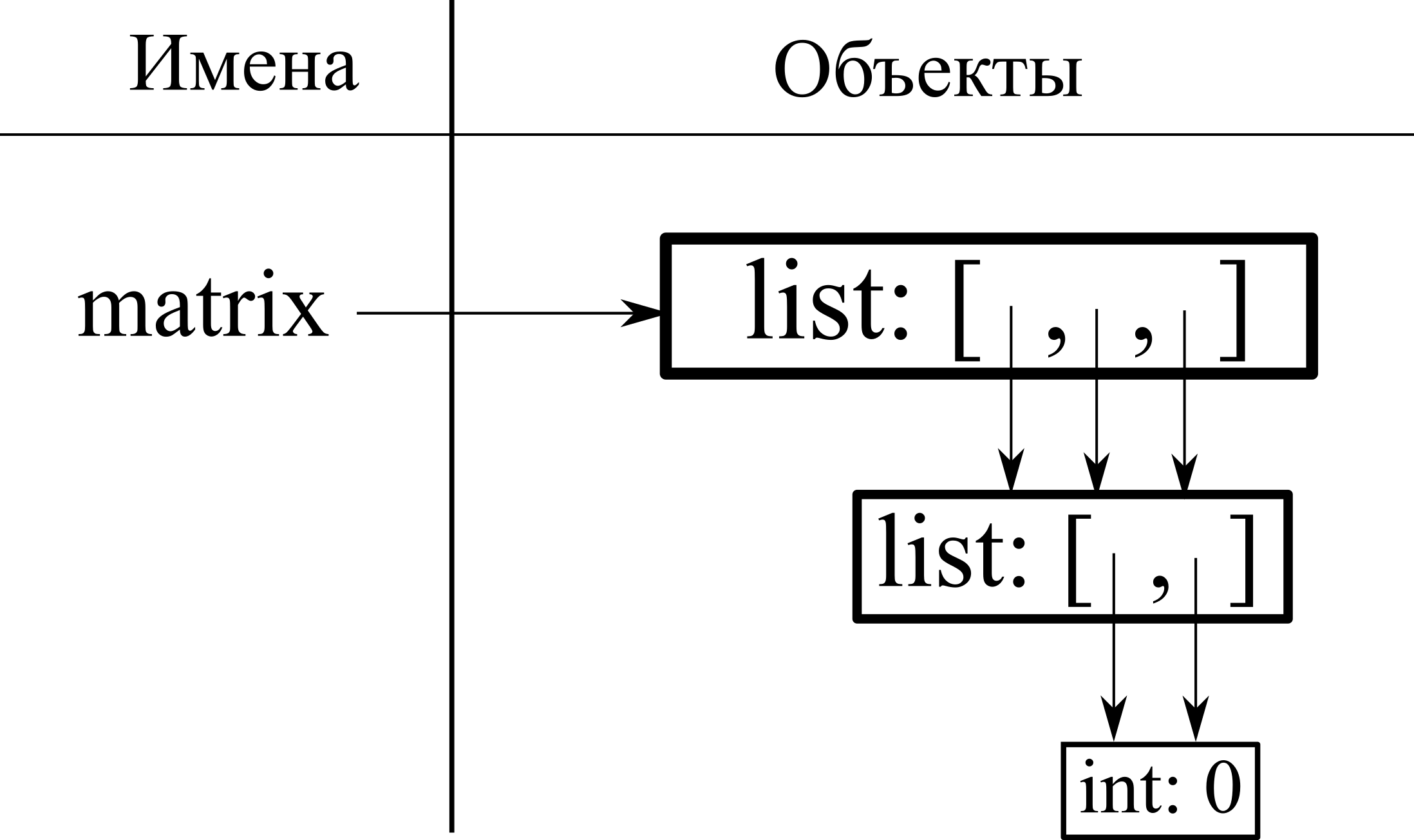
Но необходимо проявлять бдительность. Выражение x вычисляется один раз, что может привести к неожиданному поведению, если x изменяемого типа. Попробуем создать нулевую матрицу из 3 строк и 2 столбцов и поменять один элемент. Будем хранить матрицу в виде списка, элементами которого являются строки матрицы. Выражение [0] * 2 создаст одну нулевую строку матрицы. Может показаться, что выражение [[0] * 2] * 3 создаст нулевую матрицу из трех таких строк.
separator = "-" * 12 # умножение строки на число
def print_matrix(matrix):
print(separator)
for row in matrix:
print(row)
print(separator)
matrix = [[0] * 2] * 3
print_matrix(matrix)
matrix[0][0] = 1 # казалось бы изменение всего одного элемента
print_matrix(matrix)
------------
[0, 0]
[0, 0]
[0, 0]
------------
------------
[1, 0]
[1, 0]
[1, 0]
------------
Результат объясняется тем, что выражение [0] * 2 было вычислено единожды и создало один список [0, 0], на который ссылаются все указатели списка m.
Методы списка.¶
В таблице ниже перечислены основные методы списков.
Операция |
Описание |
|---|---|
|
Изменяет |
|
Срез с |
|
То же самое, что и |
|
Элементы среза с |
|
Удаляет элементы этого среза из списка. |
|
Добавляет элемент в конец (аналог |
|
Удаляет все элементы из списка. Эквивалентно |
|
Создаёт копию списка. Эквивалентно |
|
Расширяет список, добавляя все элементы итерируемого объекта в конце списка. |
|
То же, что и |
|
Вставляет элемент по заданной позиции. Первый аргумент — индекс элемента, перед которым нужно вставить элемент (второй аргумент). |
|
|
|
Удаляет первый элемент списка, который равен |
|
Обращает список на месте. |
|
Сортирует список на месте. |
Note
Все эти методы доступны также и для других изменяемых последовательностей (mutable sequence types), кроме метода l.sort().
Note
В python изменяющие объекты на месте методы обычно ничего не возвращают. Например, в итоге вычисления выражения l = l.sort() имя l будет указывать на None.
Кортежи. tuple¶
Кортеж — неизменяемый (immutable) аналог списка.
Создаётся кортеж практически также, как и список, но вместо квадратных скобок “[]” используются круглые “()” или скобки вообще опускаются. Чтобы создать кортеж из одного элемента, необходимо поставить хвостовую запятую, иначе python интерпретирует это значение или как сам элемент, если скобки круглые скобки не поставлены, или в качестве повышения приоритета, если скобки поставлены. Итого, кортеж создаётся:
Парой круглых скобок, чтобы обозначить пустой кортеж:
();
empty_tuple = ()
print(empty_tuple)
()
Используя хвостовую запятую с круглыми скобками или без, чтобы обозначить кортеж из одного элемента:
a,или(a, );
singleton_tuple = 0, # или singleton_tuple = (0, )
an_int = (0) # но не так, это int
Разделяя элементы кортежа запятыми (опционально внутри круглых скобок):
a, b, cили(a, b, c);
a_tuple = 1, 2, 3 # или a_tuple = (1, 2, 3)
Используя конструктор типа:
tuple()илиtuple(iterable);
letters = tuple("abc")
Неизменяемость кортежей¶
Кортеж под капотом является константным массивом указателей на его элементы. В отличие от списка ни размер ни содержимое этого массива менять нельзя.
a_tuple = "Earth", 3, 1.0
a_tuple[0] = 42 # ошибка
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [23], in <cell line: 2>()
1 a_tuple = "Earth", 3, 1.0
----> 2 a_tuple[0] = 42
TypeError: 'tuple' object does not support item assignment
Попытка изменить содержимое кортежа вызвало ошибку. Более точно, попытка изменить ссылку, на которую ссылается кортеж вызвало ошибку. Если объект по этой ссылке изменяемый (mutable), то изменить этот объект можно.
a_list = []
an_integer = 3
a_tuple_with_list = a_list, an_integer
a_list.append("Работает!")
print(a_tuple_with_list)
(['Работает!'], 3)
Т.е. кортеж не даёт гарантии, что его элементы не изменятся, а гарантирует лишь то, что его элементы останутся теми же самыми объектами.
Кортежи vs списки¶
Изучив свойства кортежей может возникнуть вопрос: в чем смысл использовать кортежи, если у них урезанный функционал (по сравнению со списками), а их отличительная особенность (неизменяемость) не гарантирует неизменность его элементов?
У кортежей есть два основных преимущества на фоне списков, оба из которых обусловлены их неизменяемостью:
Они работают быстрее;
От них можно вычислять
hash. Будет обсуждаться позже.
И списки и кортежи позволяют хранить произвольное количество элементов произвольного типа, но в документации рекомендуют использовать списки для хранения однородных (homogeneous) объектов, а кортежи для хранения разнородных (heterogeneous) объектов.
Имеется ввиду, что в список обычно помещают элементы, которые в некотором контексте могут обрабатываться одним и тем же кодом, в предельном случае объекты одного типа. Например, если выстраивается конструкция, в которой элементы контейнера однообразно обрабатываются в цикле, то в качестве контейнера плохо подходит кортеж. Кортежи нередко используются в качестве записей. Элемента кортежа при таком подходе
Распаковка кортежей¶
Очень часто кортежи используются для того, чтобы упаковать несколько объектов, передать их как единое целое и затем распаковать эти объекты обратно.
a_tuple = (42, 321.0, "a string")
first, second, third = a_tuple
print(first, second, third)
42 321.0 a string
Это позволяет очень выразительно писать функции, как бы возвращающие несколько значений. В качестве примера напишем функцию, решающую приведенное квадратное уравнение
решением которого являются значения
Для простоты будем считать, что даже если дискриминант \(D\) нулевой и существует единственный корень кратности два, что существует два одинаковых корня.
Сравнительно наивная (численно не устойчивая) реализация этого алгоритма выглядит следующим образом.
from math import sqrt
def quadratic_solve(b, c):
"Solves an equation x^2 + bx + c = 0"
# linear case
D = b * b - 4. * c
term1 = -b / 2.
term2 = sqrt(abs(D)) / 2.
# real roots
if D >= 0:
return term1 - term2, term1 + term2
# complex roots
return complex(term1, -term2), complex(term1, term2)
Обратим внимание на то, как возвращаются значения из этой функции:
return term1 - term2, term1 + term2
в случае двух действительных корней и
return complex(term1, -term2), complex(term1, term2)
в случае двух комплексных корней.
В обоях случаях на самом деле перед возвращением конструируется кортеж из двух значений. Вызывающий код при желании может сразу же эти два значения и распаковать.
В качестве примера решим уравнение \(x^2 - 5x + 6 = (x-2)(x-3) = 0\) этой функцией и сразу распакуем два корня по разным переменным.
x1, x2 = quadratic_solve(-5, 6)
print(x1, x2)
2.0 3.0
Функция divmod — примером встроенной возвращающей 2 значения функции.
d, m = divmod(11, 3)
print(d, m)
print(11 // 3, 11 % 3)
3 2
3 2
Note
Распаковывать можно и списки, но это кроме того, что вынуждает писать дополнительные скобочки, ещё и работает медленнее.
Кортежи в качестве записей¶
Кортежи нередко использую в качестве записей, т.е. таких мини-структур данных с полями.
Например, если в рамках программы планеты описываются названиями, количество спутников и их массой относительно массы земли, то для их описания можно использовать кортежи из трех элементов.
planets = [
("Меркурий", 0, 0.0055),
("Венера", 0, 0.815),
("Земля", 1, 1.),
("Марс", 2, 0.107),
("Юпитер", 62, 317.8),
("Сатурн", 34, 95.2),
("Уран", 27, 14.37),
("Нептун", 13, 17.15),
]
Заметим, что список planets хранит однородные объекты — кортежи из трех элементов, описывающие планеты, а каждый из кортежей состоит из разнородных объектов, т.к. они представляют из себя запись о планете.
Элементы списка planets удобно обрабатывать одним и тем же кодом, так как все они имеют одинаковую структуру. Каждую запись о планете легко распаковать по переменным согласно полям этой записи.
def print_planet(planet):
name, n_moons, mass = planet
print(f"Планета {name} имеет {n_moons} спутников. Её масса составляет {mass} земных масс.")
for planet in planets:
print_planet(planet)
Планета Меркурий имеет 0 спутников. Её масса составляет 0.0055 земных масс.
Планета Венера имеет 0 спутников. Её масса составляет 0.815 земных масс.
Планета Земля имеет 1 спутников. Её масса составляет 1.0 земных масс.
Планета Марс имеет 2 спутников. Её масса составляет 0.107 земных масс.
Планета Юпитер имеет 62 спутников. Её масса составляет 317.8 земных масс.
Планета Сатурн имеет 34 спутников. Её масса составляет 95.2 земных масс.
Планета Уран имеет 27 спутников. Её масса составляет 14.37 земных масс.
Планета Нептун имеет 13 спутников. Её масса составляет 17.15 земных масс.
Строки. str¶
Строки — неизменяемые последовательности (immutable sequence type), предназначенные для работы с текстовыми данными в кодировке unicode. То, что python из коробки поддерживает unicode значительно упрощает работу с текстом в общем случае, и написание web-ориентированных приложений в частности. Кроме того, что unicode помещается английский язык и все спецсимволы, в него также помещаются русский, китайский, арабский и многие другие языки. Ещё в него помещаются emoji.
hello_in_russia = "Привет!"
hello_in_japanese = "こんにちは"
snake_emoji = "🐍"
print(hello_in_russia, hello_in_japanese, snake_emoji)
Привет! こんにちは 🐍
Так как при решении физических и математических задач работа с текстом встречается сравнительно редко, то тут будет приведен поверхностный обзор возможностей python, не затрагивающий кодировок и не покрывающий огромное множество методов обработки.
Можно считать, что это массив, который содержит в себе unicode коды символов в этой строке. В python нет отдельного типа данных под один символ, т.е. символ представляет собой строку длинны 1.
Строки — последовательности, а значит можно обратившись по индексу получить символ (строку из одного символа), но последовательности неизменяемые, т.е. изменить любой символ нельзя. Чтобы изменить строку, нужно создать новую.
Создать строки можно огромным количеством способом. Рассмотрим самые основные из них.
Можно задавать строки в одинарных (апострофы) и двойных кавычках:
s1 = 'Hello, world!' s2 = "Hello, world!"
Это может пригодиться, если вы хотите поместить внутрь строки символы кавычек первого или второго типа. Например, апостроф можно поместить внутри двойных кавычек, а двойные кавычки внутри одинарных:
s1 = '"Э́врика!" - Архимед' s2 = "What's up."
Можно задавать строки, допускающие перенос строки внутри, с помощью троекратных одинарных или двойных кавычек:
s = '''
"Modern programs must handle Unicode —
Python has excellent support for Unicode,
and will keep getting better" - Guido van Rossum.
'''
print(s)
"Modern programs must handle Unicode —
Python has excellent support for Unicode,
and will keep getting better" - Guido van Rossum.
Очень часто используется для документации функций. Например, ниже приводится пример из исходного кода функции complex.
def complex(real=0.0, imag=0.0):
"""Form a complex number.
Keyword arguments:
real -- the real part (default 0.0)
imag -- the imaginary part (default 0.0)
"""
if imag == 0.0 and real == 0.0:
return complex_zero
...
Также существует огромное количество функций и методов, которые позволяют создавать строки из уже существующих строк и объектов других видов.
Самый простой пример — конструктор класса str. Она преобразует объект в читабельную строку (если объект допускает это) и всегда неявно вызывается, если объект подаётся на вход функции print.
from math import pi
print(str(pi))
3.141592653589793
Строковые методы¶
У строк есть огромное количество методов, которые обычно возвращают отредактированную тем или иным образом строку (всегда новую, т.к. строки неизменяемы). С полным списком методов можно ознакомиться по ссылке, а здесь будут упомянуты самые необходимые.
Метод strip удаляет переданные ему в качестве параметра символы по обоим краям строки. По умолчанию удаляет пробелы. Существуют аналогичные методы lstrip и rstrip, которые делают тоже самое, но только с левого конца и с правого конца соответственно.
s = " spacious "
print(f"|{s}|")
print(f"|{s.strip()}|")
| spacious |
|spacious|
Метод replace принимает два обязательных параметра old и new и заменяет все вхождения old в строке на new. Передавая в качестве new пустую строку, можно использовать этот метод для удаления.
s = "Иван любит математику."
print(s.replace("Иван", "Александр"))
Александр любит математику.
Методы ljust, rjust и center расширяют строку пробелами, но с разным выравниванием исходной строки внутри результирующей:
ljust выравнивает по левому краю, т.е. добивает пробелами до нужной строки с правого края;
rjust выравнивает по правому краю, т.е. добивает пробелами до нужной строки с правого края;
center выравнивает по центру.
line_width = 80
title = "Knock"
text = "The last man on Earth sat alone in a room. There was a knock at the door..."
author = "Fredric Brown"
print(title.center(line_width))
print(text.ljust(line_width))
print(author.rjust(line_width))
Knock
The last man on Earth sat alone in a room. There was a knock at the door...
Fredric Brown
Метод split режет строку на части, используя переданный в качестве параметра разделитель (по умолчанию пробел). Возвращает список строк.
x = "1,2,3"
values = x.split(",")
print(values)
['1', '2', '3']
Метод join является по сути дела обратным к методу split. Он объединяет список переданных ему строк в качестве обязательного параметру в одну, используя в качестве разделителя строку, от которой этот метод был вызван.
" ".join(values)
'1 2 3'
Форматирование строк¶
В python есть минимум четыре способа форматирования строк. Первым, и пожалуй самым неправильным, является склеивание строки вручную.
an_int = 42
a_float = pi
a_name = "Иван"
print(a_name + " больше всего любит два числа: " + str(an_int) + " " + str(a_float) + ".")
Иван больше всего любит два числа: 42 3.141592653589793.
Вторым подходом является форматирование в стиле C, который опирается на перегруженность оператора "%" для строк. Полные возможности такого подхода описаны по ссылке.
print("%s больше всего любит два числа: %i и %f." % (a_name, an_int, a_float))
Иван больше всего любит два числа: 42 и 3.141593.
Третьим подходом является использование метода строк format, полные возможности которого описаны по ссылке.
template = "{0} больше всего любит два числа: {1} и {2}."
print(template.format(a_name, an_int, a_float))
Иван больше всего любит два числа: 42 и 3.141592653589793.
Четвертым и самым новым подходом является использование f-строк (f-strings)которым и отдаёт предпочтение автор. f-строки позволяют использовать выражения python прямо внутри строки, за счет чего нередко предлагают самый наглядный способ форматирования строк.
s = f"{a_name} больше всего любит два числа: {an_int} и {a_float}."
print(s)
Иван больше всего любит два числа: 42 и 3.141592653589793.
Какой из них выбрать — по большей части дело вкуса.
Форматирование в стиле C было введено в python вместе с самой первой версией языка и гарантированно будет работать на более старых версиях python. Из-за схожести с форматирование в языке C некоторым программистам легче воспринимать код, форматирующий строки в таком стиле.
Метод format более наглядный и допускает более гибкое форматирование, чем форматирование в стиле C. Кроме того такой подход позволяет переиспользовать одну и ту жу строку для многократного форматирования, что может быть очень эффективно, если в вашей программе необходимо регулярно подставлять какие-то значения в определенные позиции одного и того же шаблона. Никакими другими перечисленными здесь методами такого эффекта не достичь, но в ряде ситуация оправданным будет использовать для таких целей класс Template из модуля string.
f-строки введены сравнительно недавно и наверное представляют собой самый наглядный способ форматирования строк на сегодня, хотя и не все с этим согласны. Ниже будут коротко описаны самые основы этого способа.
f-строки.¶
Чтобы писать f-строки, необходимо ставить перед строкой символ f или F. Далее в самом простом варианте внутри одинарных фигурных скобок “{}” можно указывать python выражение, результат вычисления которых появится вместо фигурных скобок в результирующей строке.
s = f"abc{expression}def"
print(f"{2 + 2}")
4
Опционально можно указать спецификацию форматирования этого выражения, указав её после выражения через двоеточия внутри той же пары фигурных скобок.
s = f"abc{expression:specification}def"
Самая простая спецификация — обеспечивание необходимой ширины строки с выравниванием, т.е. достижение аналогичного строковым методам ljust, rjust и center эффекта, для чего после двоеточие ставится один из символов “<”, “>” и “^” и целое положительное число.
s = f"{expression:[alignment]width}"
Note
Квадратные скобки “[]” указывают на опциональность их содержимого.
print(f"{title:^80}")
print(f"{text:<80}")
print(f"{author:>80}")
Knock
The last man on Earth sat alone in a room. There was a knock at the door...
Fredric Brown
Подобные выражения могут быть использованы для выравнивания столбцов в тексте. В качестве примера рассмотрим следующий код и его вывод.
years = [99, 100, 101]
centuries = ["I", "II", "II"]
for i in range(3):
print(f"Год {years[i]} => {centuries[i]}-й век")
Год 99 => I-й век
Год 100 => II-й век
Год 101 => II-й век
Эстетически может не понравится, что значения в первой строке “поехали” влево относительно значений в других строках. Чтобы исправить это, можно указать все значения с необходимой шириной и выравниванием.
for i in range(3):
print(f"Год {years[i]:>3} => {centuries[i]:>3}-й век")
Год 99 => I-й век
Год 100 => II-й век
Год 101 => II-й век
Чтобы добивать строку до необходимой ширины не пробелом, а другим символом, необходимо указать этот символ перед спецификатором выравнивания.
s = f"{expression:[filler][alignment]width}"
for power in range(10):
print(f"{10 ** power:0>10}")
0000000001
0000000010
0000000100
0000001000
0000010000
0000100000
0001000000
0010000000
0100000000
1000000000
При форматировании чисел с плавающей запятой можно указать количество значащих цифр.
s = f"{expression:[filler][alignment]width[.precision]}"
from math import pi
print(f"{pi:>16.2}")
print(f"{pi:>16.5}")
print(f"{pi:>16.15}")
3.1
3.1416
3.14159265358979
Кроме того можно фиксировать формат вывода. Доступные значения:
s = f"{expression:[filler][alignment]width[.precision][type]}"
Среди допустимых значений:
“
f” — число с фиксированной точкой;“
e” — научный формат;“
%” — процент;и др.
x = 5 / 13
print(f"{x:.5}")
print(f"{x:>.5f}")
print(f"{x:>.5e}")
print(f"{x:>.5%}")
0.38462
0.38462
3.84615e-01
38.46154%