pd.Series
Contents
pd.Series¶
Создание¶
Создать pd.Series можно:
Из скаляра (число, строка);
Из итерируемого объекта (
list,np.arrayи т.д.);Из словаря.
Создание pd.Series из скаляра создаёт столбец с одним элементом.
import pandas as pd
import numpy as np
s = pd.Series("abc")
s
0 abc
dtype: object
Вывод сообщает, что s — столбец из одного элемента "abc" типа object, индекс которого равен 0.
object— самый общий тип данных в столбце. Вpd.Seriesтипаobjectможно хранить данные любого типа, но этого следует по возможности избегать из соображений производительности, читабельности и удобства применений методов библиотекиpandas. Указать тип столбца можно дополнительным параметромdtype(“string” для строк).при создании
pd.Seriesскаляра, индекс единственного элемента будет равен 0. Можно явно указать индекс с помощью параметраindex.
s = pd.Series("abc", dtype="string", index=[42])
s
42 abc
dtype: string
Создание столбцов из одного элемента применяется не очень часто, хотя и встречается. Более содержательный пример — создание pd.Series из списка или массива NumPy.
data = [7, 12, 42]
s = pd.Series(data)
s
0 7
1 12
2 42
dtype: int64
Создан столбец с элементами из списка data с такими индексами, какие они были в исходном списке.
У объекта pd.Series можно спросить значения аттрибутом values (возвращается np.array)
s.values
array([ 7, 12, 42], dtype=int64)
а индекс соответствующим атрибутом index
s.index
RangeIndex(start=0, stop=3, step=1)
Если индекс не указывается явно, то создаётся RangeIndex, т.е. как бы смещение от начала массива. Как и в случае скаляра, можно было бы явно указать индекс при создании столбца.
При создании pd.Series из словаря, ключи попадают в индекс столбца, а значения попадают в данные столбца.
d = {
"a": 7,
"b": 12,
"c": 42
}
s = pd.Series(d)
s
a 7
b 12
c 42
dtype: int64
Индексация¶
Получать значение из столбца можно двумя способами:
по метке (используя индекс столбца);
по смещению.
Warning
Оператор [] по умолчанию возвращает значение по метке, но если индекс столбца не целочисленного типа, а значение между скобками — целое число, то индексирует по смещению. Т.е. есть некоторая неоднозначность в таком способе индексации, что может привести к ошибкам. Лучшей практикой считается применение методов pd.Series.loc и pd.Series.iloc, чтобы явно указать каким способом следует осуществлять индексацию.
Выражение s.loc[index] возвращает элемент(ы) столбца с индексом index, а метод s.iloc[i] возвращает i-й элемент столбца по смещению от начала (как оператор [] списков и массивов NumPy). Продемонстрируем это на примере столбца с индексом из символов.
symbols = "abcdefg"
s = pd.Series(data=range(len(symbols)), index=list(symbols))
print(s)
print(f'loc["a"]: {s.loc["b"]}, iloc[1]: {s.iloc[1]}')
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
loc["a"]: 1, iloc[1]: 1
Т.е. до одного и того же элемента серии можно достучаться разными способами. Индексация по смещению (iloc) аналогична NumPy (в том числе и срезы). Индексация по индексу (loc) больше похожа на получение значения по ключу в словаре. Можно осуществлять срезы и по индексу, но в данном случае правая граница попадает в срез.
s["b":"f"]
b 1
c 2
d 3
e 4
f 5
dtype: int64
Warning
В одном столбце у разных элементов могут быть одинаковые метки (дубликаты). Метод loc возвратит все элементы с такой меткой, но срезы в таком случае могут сломаться из-за неоднозначности определения границ среза.
Обоими методами можно получить сразу несколько элементов pd.Series, передав в них список смещений/меток.
print(s.loc[["a", "d", "e"]])
print(s.iloc[[0, 3, 4]])
a 0
d 3
e 4
dtype: int64
a 0
d 3
e 4
dtype: int64
Индексация по смещению работает чуть быстрее, чем индексация по меткам, но последняя предоставляет более удобный функционал. Позже будет раскрыто, что в таблицах (DataFrame) эти же метки используются для индексации по строкам. Это позволяет:
осуществлять быстрый поиск строк таблицы по метке. Это может значительно ускорить программы, постоянно осуществляющие такие запросы по значению какого-то конкретного столбца (или пары столбцов,
pandasдопускает MultiIndex), т.к. такая индексация по меткам гораздо быстрее, чем линейный (и даже бинарный) поиск по данным. Однако если в индексе много дубликатов, то эффективность такого способа индексации уменьшается;Выравнивать данные разных столбцов между собой. Это может пригодиться, если данные приходят из разных источников и упорядоченны по-разному, но все из них помечены однообразно. В таком случае можно не затрудняясь выравнять эти данные между собой средствами
pandas.
Изменяемость pd.Series¶
Аналогично с массивами NumPy, можно изменять содержимое ячейки/среза, но нельзя изменять размер (длину) столбца.
Например, изменить содержимое ячейки по метке a можно сделать следующим образом.
s.loc['a'] = 42
s
a 42
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
С изменением размера следует быть аккуратным. Следующая операция как бы увеличит размер столбца s. Но pandas перевыделяет память, копирует данные старого столбца и дозаписывает новое значение при каждом добавлении нового значения в столбец или новой строки в таблицу. Т.е. использовать объекты pandas для накопления строк по одной крайне неэффективно. Если есть такая необходимость, то обычно данные накапливают в контейнерах python (список, словарь) и трансформируют в pandas объект в самом конце или по накоплении некого блока информации. Альтернативой служит создание большой таблицы/столбца и работа только с первыми n строками, увеличивая n при необходимости.
s.loc['z'] = 42
s
a 42
b 1
c 2
d 3
e 4
f 5
g 6
z 42
dtype: int64
Операции над pd.Series¶
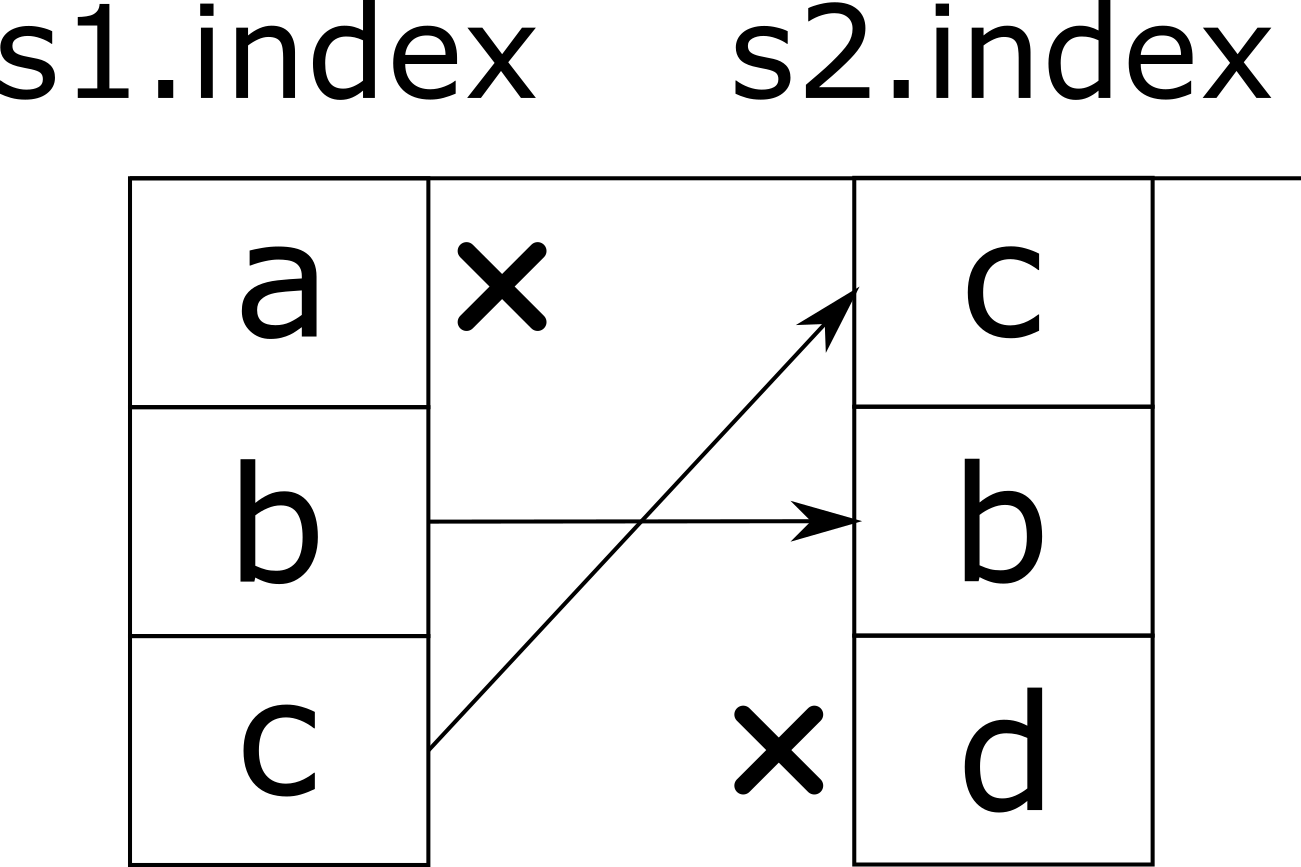
При выполнении операций над столбцами метки играют важную роль. Например, при сложении двух столбцов складываются значения с одинаковыми метками. Индекс результирующего столбца — объединение индексов столбцов слагаемых, а напротив тех меток, которые присутствуют в индексе только одного столбца записывается значение np.nan.
s1 = pd.Series([1, 2, 3], index=["a", "b", "c"], dtype="int")
s2 = pd.Series([10, 20, 30], index=["c", "b", "d"], dtype="int")
s = s1 + s2
s
a NaN
b 22.0
c 13.0
d NaN
dtype: float64
Рисунок ниже иллюстрирует, что произошло.
Также можно заметить, что данные результирующего столбца имеют тип float64, несмотря на то, что исходные столбцы целочисленного типа. Это объясняется тем, что появившееся значения np.nan имеют такой тип.
Большинство методов массивов NumPy переопределены в pandas для pd.Series таким образом, чтобы обрабатывать пропущенные значения, которые моделируются с помощью np.nan.
s.mean()
17.5
Все логические операции работают аналогично NumPy (сравнение NaN с чем угодно всегда False) и также допускается логическая индексация (в случае булевой маски mask, .loc[mask] и .iloc[mask] делают одно и тоже, поэтому тут оправданно применение простых квадратных скобок []).
s[s > 10]
b 22.0
c 13.0
dtype: float64